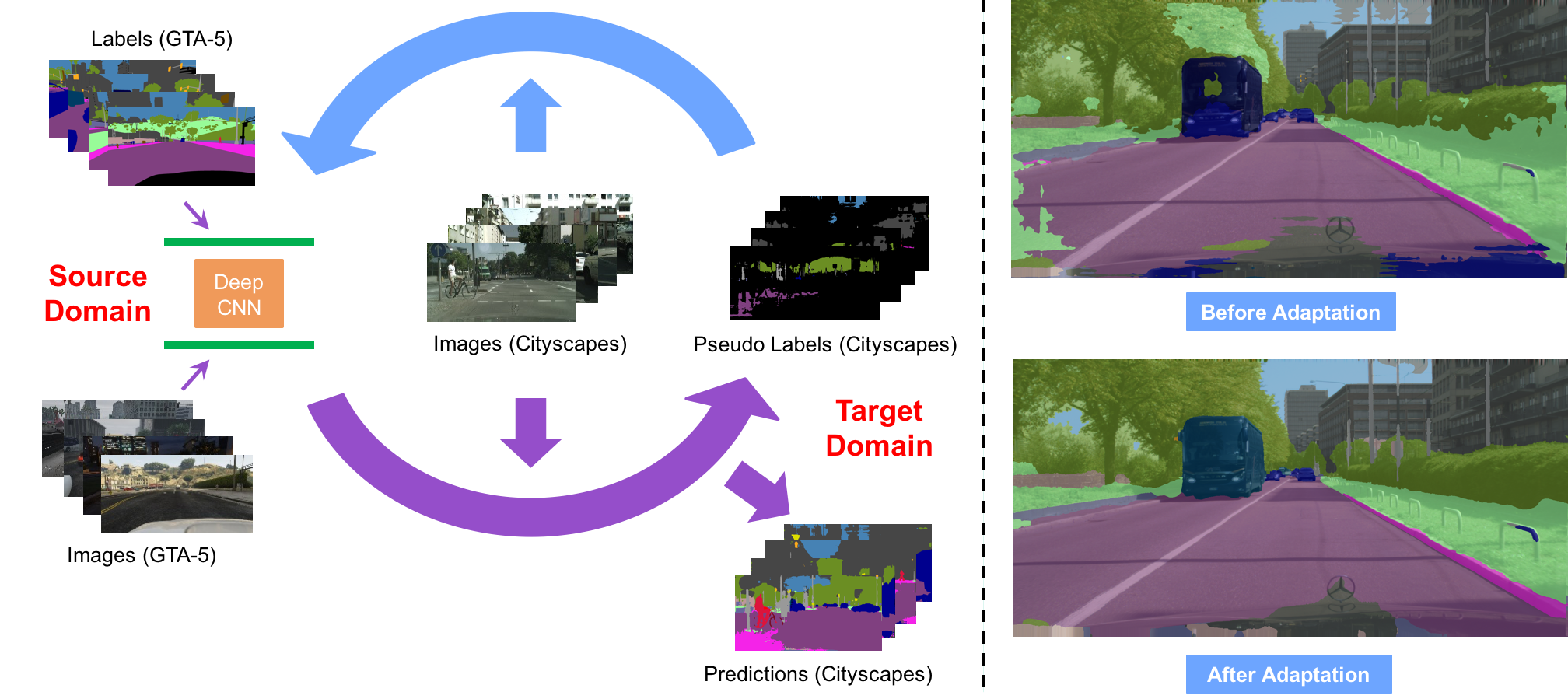
 Recent deep networks achieved state of the art performance on a variety of semantic segmentation tasks. Despite such progress, these models often face challenges in real world “wild tasks” where large difference between labeled training/source data and unseen test/target data exists. In particular, such difference is often referred to as “domain gap”, and could cause significantly decreased performance which cannot be easily remedied by further increasing the representation power. Unsupervised domain adaptation (UDA) seeks to overcome such problem without target domain labels. In this paper, we propose a novel UDA framework based on an iterative self-training (ST) procedure, where the problem is formulated as latent variable loss minimization, and can be solved by alternatively generating pseudo labels on target data and re-training the model with these labels. On top of ST, we also propose a novel class=balanced self-training (CBST) framework to avoid the gradual dominance of large classes on pseudo-label generation, and introduce spatial priors to refine generated labels. Comprehensive experiments show that the proposed methods achieve state of the art semantic segmentation performance under multiple major UDA settings.
Recent deep networks achieved state of the art performance on a variety of semantic segmentation tasks. Despite such progress, these models often face challenges in real world “wild tasks” where large difference between labeled training/source data and unseen test/target data exists. In particular, such difference is often referred to as “domain gap”, and could cause significantly decreased performance which cannot be easily remedied by further increasing the representation power. Unsupervised domain adaptation (UDA) seeks to overcome such problem without target domain labels. In this paper, we propose a novel UDA framework based on an iterative self-training (ST) procedure, where the problem is formulated as latent variable loss minimization, and can be solved by alternatively generating pseudo labels on target data and re-training the model with these labels. On top of ST, we also propose a novel class=balanced self-training (CBST) framework to avoid the gradual dominance of large classes on pseudo-label generation, and introduce spatial priors to refine generated labels. Comprehensive experiments show that the proposed methods achieve state of the art semantic segmentation performance under multiple major UDA settings.